Pandas 的 groupby 語法
簡介
Groupby 是 Pandas 中的一個很強大的操作方法。
它可以將資料「分組」,之後在分組的資料上做運算,然後再將運算的結果組合起來。
舉例而言,老師想看一年級中,不同班級的「數學」以及「英文」成績的平均值 (依班級分組,在分組中做平均值運算)。
國家想統計不同都市中收入的中位數 (依都市分組,在分組中取中位數),都可以使用 groupby 運算達成。
一般來說,如果資料中有「類別變數」出現,那通常就會有 groupby 的需求。
類別變數例如:性別 (男/女),班級 (1A/1B/1C),等級 (A/B/C),洲 (亞洲/非洲/美洲),膚色 (黑/白/黃)…等。
Groupby 是一個 split-apply-combine 操作

Split 操作
Split 用來將資料分組,例如上圖中,將資料依班級屬性來分割 (split)。
Apply 操作
Apply 則是將某些運算作用在分割後的組別。
例如上圖中,我們將「取平均」(
mean()) 這個運算作用在分割出來的組別上。
在 Pandas 的文獻中,可以用在 apply 階段的操作有:
- 聚合函數:例如 mean(), count(), min(), max()…等
- 過濾操作 (filter):以分組的方式來過濾資料,例如依據分組後的平均埴,把某些組別濾掉 (把均值小於 30 的組別濾除)
- 轉換操作 (Transformation):以分組的方式來轉換資料,例如將群組中的空值依群組中的平均值填滿。例如我們將資料分成「男性」,「女性」兩組。這兩組的體重資料中,有些人是空值。於是男性的組別中,我們用男性體重的均值填入,女性組別中,則用女性體重的均值來填。
Combine 操作
最後 Pandas 會將 apply 階段的執行結果聚合在一起,呈現給使用者。
底下就用範例示範 Pandas 的 groupby 語法的使用方式。
造出示範資料集
使用底下的語法造出示範用的資料集。

分組
呼叫 groupby 後,就可以對資料分組。
groupby() 中的參數可以是「一個欄位」,也可以是「多個欄位」。
底下示範一個欄位的 groupby。
裏面資料的內容如同上圖中 split 階段的結果。
我們也可以針對多個欄位來分組,語法如下所示。
在上面的程式碼中,groupby 中傳入的參數是一個串列,包含多個欄位名稱。
觀察分組內的資料

因為結果是一個 dataframe,所以可以用 iloc,loc,at,iat 來取得裏面的資料。
執行結果如下圖所示:

執行結果如下圖所示:

所以要存取某個 group 時,要用 tuple 來指定要存取的組別。
下面是取得 1A 班級中,數學分數 95 分組別的資料。
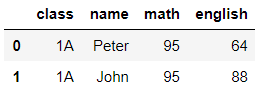

first() 和 head(1) 主要的差別在於 first 會跳過空值,但 head 不會。
所以要是第一筆資料是空值的話,first 會跳過它,秀第2筆,但 head 會忠實的秀出來。

使用 for...loop 來取得所有 group 的資料
我們也可以使用 for loop 來取得每個 group 中的資料。

觀察分組中的統計資料
分完組後,我們想知道每個分組中的統計資料。
例如
- 每一分組中有幾筆資料?
- 每一分組中,數學的平均值?英文的平均值?
- 每一分組中,數學的最大值?英文的最大值?
- 每一分組中,僅取出數學的平均值。
- 在每一分組中,計算數學的平均值,以及最大值。
底下分別用例子來解說。
用 size() 來觀察每個 group 中有幾筆資料
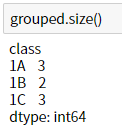
size() 函式可以秀出每個 group 中有幾筆資料。
在底下的例子中,可以看出 1A 中有 3 筆資料。1B 有 2 筆資料,而 1C 有 3 筆資料。
取得數學及英文的平均成績
我們可以使用 mean() 操作,即可秀出數學,以及英文的平均成績。

用 max() 取得最高成績

當然,我們還可以使用
- min() 取得最小值
- median() 取得中位數
- std() 取得標準差
- var() 取得變異數
- count() 取得群組內有幾筆資料,這個函式會忽略 missing value,但 size() 不會 。
- quantile() 取得幾分位數。

上面每個函式一個一個試來取得資料蠻麻煩的。
我們可以呼叫 describe(),直接把所有的統計量都算出來。
底下的例子中,秀出了數學,以英文分數的統計量,包含四分位數。

取得單一個欄位的統計資料
前面的示範都是一次取得數學,以及英文的統計資料。
要是我只想取得數學的統計資料呢?
底下的範例示範了如何取得數學的最大值。

但有時候,我們想要找出的,是「誰」是最高分。
而不是「最高分是幾分」。
這個時候就要用到 idxmax() 方法了。
idxmax() 會把每個 group 中最高分的 index 回傳回來 (以 series 的型別),之後再搭配 loc 方法,即可取得對應的資料。

之後再搭配 loc 方法,即可取得每個 group 中,數學最高分者的所有資料了。

使用 agg 方法,在單一欄位上,取得多個統計量
在前面的範例中,我們針對數學這個欄位,取得最大值。
那要是我們想同時計算最大值,最小值呢?
那我們可以呼叫 agg 方法,把要計算的統計函式傳入即可。
記得,只要傳入函式的「名字」即可,後面的 () 可以不用寫。

結論
在這篇文章中,我們說明了 Pandas groupby 的使用方式。
Groupby 最常應用的場景是用在資料中具有「分組」的屬性,我們可以透過 groupby 來分組資料,並取得每個分組中的資訊。
我們談到了 groupby 的是基於 split-apply-combine 的操作,並說明每個操作中較具代表性方法的使用方式。
Groupby 還有許多實用的用法,有機會再寫文章中明。
本文章有許多操作是參考 Dataschool 的 youtube 頻道,以及 FB 的文章。推薦想學習 Pandas 的網友參考。


網誌管理員已經移除這則留言。
回覆刪除謝謝老師,找了很久才發現這篇如此詳盡的解說了groupby函數,清晰又明白!
回覆刪除非常感謝您的分享與解說,非常詳細,收穫良多!
回覆刪除